
BRIDGES
The BRIDGES program is an innovative initiative jointly led by the Departments of Medicine (DOM) and Family & Community Medicine (DFCM) at the University of Toronto.
View Project Profile
Centre for exceLlence in Economic Analysis Research
Applied Health Research Centre
Knowledge Translation Services
The HUB integrates health economics expertise from the Centre for exceLlence in Economic Analysis Research (CLEAR), clinical research methods and operations infrastructure of the Applied Health Research Centre (AHRC) and knowledge translation expertise from BreaKThrough Knowledge Translation (KT) Services.
We are housed at the Li Ka Shing Knowledge Institute of St. Michael’s Hospital and fully affiliated with the University of Toronto, the largest health research entity in Canada.
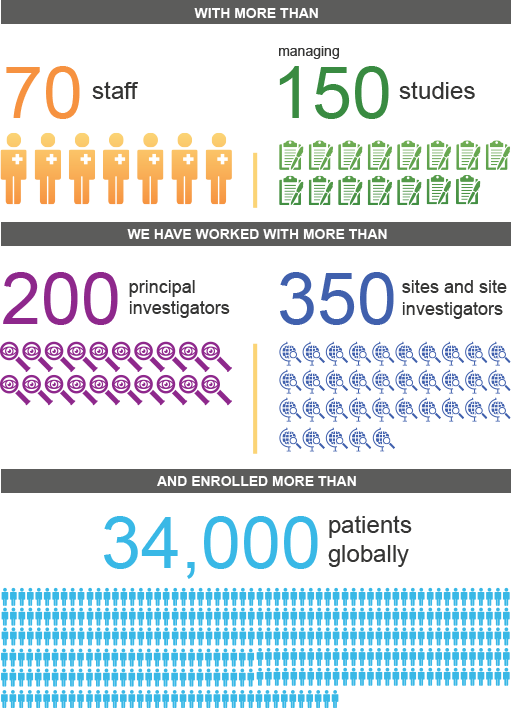
We want to use them to help make your study a success.
Our scientific leaders bring world-renowned expertise in designing and managing global clinical trials and studies, patient registries, qualitative studies, health economic evaluations, systematic reviews and knowledge translation research.
We've built strong relationships and established local and global networks of thousands of experts including academic researchers, clinicians, statisticians and epidemiologists, and hundreds of key opinion leaders.
We work with academic investigators, small, medium and large organizations, commercial and not-for-profits. Our infrastructure can be used as much or as little as you need. We strive to provide customized health research solutions that fit your project goals through a combination of the following services.
The BRIDGES partnership with the HUB has been critical to making BRIDGES a success. It has provided us and our project teams with centralized access to a wide range of expertise and has helped us build stronger working relationships, increased the consistency of our work and enhanced our operational efficiency. Dr. Michael Schull, Co-Principal Implementer of BRIDGES

Facilitator: Dr. Peter Jϋni, and Judith Hall Date: June 21, 2018: 9:30am – 11:30am Registration: Please register...
Read More
Facilitator: Chris Ducharme Date: May 17, 2018 : 10:00am – 11:00am Registration: Please register online to attend this session....
Read More
Facilitators: Dr. Janet Parsons and Natalie Baker Date: February 23rd, 2018 – 9:30am – 11:00am Registration: Please register...
Read More
Facilitator: Amr Sharaf Date: August 24th, 2017 10:30am-12:00pm Registration: Please register online to attend this...
Read MoreThank you for contacting The Hub Health Research Solutions at St. Michael's Hospital.
We have received your email and will be in touch soon!
Li Ka Shing Knowledge Institute
30 Bond Street
Toronto, ON, M5B 1W8
hubresearch@smh.ca




